1. Security News – 2026-04-01
Wed Apr 01 2026 00:00:00 GMT+0000 (Coordinated Universal Time)
The Hacker News
Cybersecurity news and insights
Android Developer Verification Rollout Begins Ahead of September Enforcement - March 31, 2026
Google on Monday said it’s officially rolling out Android developer verification to all developers to combat the problem of bad actors distributing harmful apps while “hiding behind anonymity.” The development comes ahead of a planned verification mandate that goes into effect in Brazil, Indonesia, Singapore, and Thailand this September, before it expands globally next year. As part of this
Google Security Blog
Security insights from Google
VRP 2025 Year in Review - March 31, 2026
2025 marked a special year in the history of vulnerability rewards and bug bounty programs at Google: our 15th anniversary 🎉🎉🎉! Originally started in 2010, our vulnerability reward program (VRP) has seen constant additions and expansions over the past decade and a half, clearly indicating the value the programs under this umbrella contribute to the safety and security of Google and its users, but also highlighting their acceptance by the external research community, without which such programs cannot function.
Coming back to 2025 specifically, our VRP once again confirmed the ongoing value of engaging with the external security research community to make Google and its products safer. This was more evident than ever as we awarded over $17 million (an all-time high and more than 40% increase compared to 2024!) to over 700 researchers based in countries around the globe – across all of our programs.
Vulnerability Reward Program 2025 in Numbers


Want to learn more about who’s reporting to the VRP? Check out our Leaderboard on the Google Bug Hunters site.
VRP Highlights in 2025
In 2025 we made a series of changes and improvements to our VRP and related initiatives, and continued to invest in the security research community through a series of focused events:
The new, dedicated AI VRP was launched, underscoring the importance of this space to Google and its relevance for external researchers. Previously organized as a part of the Abuse VRP, moving into a dedicated VRP has gone hand in hand with improvements to the rules, offering researchers more clarity on scope and reward amounts.
Similarly, the Chrome VRP now also includes reward categories for problems found in AI features.
We launched a patch rewards program for OSV-SCALIBR, Google’s open source tool for finding vulnerabilities in software dependencies. Contributors are rewarded for providing novel OSV-SCALIBR plugins for inventory, vulnerability, or secret detection that expand the tool’s scanning capabilities. Besides strengthening the tool’s capabilities for all users, user submissions already helped us uncover and remediate a number of leaked secrets internally!
As part of Google’s Cybersecurity Awareness Month campaign in October, we hosted our very own security conference in Mexico City, ESCAL8. The conference included init.g(mexico), our cybersecurity workshop for students, HACKCELER8, Google’s CTF finals, and a Safer with Google seminar, sharing technical thought leadership with Mexican government officials.
bugSWAT, our special invite-only live hacking event, saw several editions in 2025 and delivered some outstanding findings across different areas:
We hosted our first dedicated AI bugSWAT (Tokyo) in April which yielded a whopping 70+ reports filed and over $400,000 in rewards issued.
We continued the momentum in early summer with Cloud bugSWAT (Sunnyvale) in June resulting in 130 reports, with $1,600,000 in rewards paid out.
Next in line was bugSWAT Las Vegas in August, leading to 77 reports and rewards of $380,000.
And finally, as part of ESCAL8 in Mexico City, bugSWAT Mexico focused on many different targets and spaces including AI, Android, and Cloud, and resulted in the filing of 107 reports, totalling $566,000 in rewards to date.
Looking for more details? See the extended version of this post on the Security Engineering blog for reports from individual VRPs such as Android, Abuse, AI, Cloud, Chrome, and OSS, including specifics concerning high-impact bug reports and focus areas of security research.
What’s coming in 2026
In 2026, we remain fully committed to fostering collaboration, innovation, and transparency with the security community by hosting several bugSWAT events throughout the year, and following up with the next edition of our cybersecurity conference, ESCAL8. More broadly, our goal remains to stay ahead of emerging threats, adapt to evolving technologies, and continue to strengthen the security posture of Google’s products and services – all of which is only possible in collaboration with the external community of researchers we are so lucky to collaborate with!
In this spirit, we’d like to extend a huge thank you to our bug hunter community for helping us make Google products and platforms more safe and secure for our users around the world – and invite researchers not yet engaged with the Vulnerability Reward Program to join us in our mission to keep Google safe (check out our programs for inspiration 🙂)!
Thank you to Tony Mendez, Dirk Göhmann, Alissa Scherchen, Krzysztof Kotowicz, Martin Straka, Michael Cote, Sam Erb, Jason Parsons, Alex Gough, and Mihai Maruseac.
Tip: Want to be informed of new developments and events around our Vulnerability Reward Program? Follow the Google VRP channel on X to stay in the loop and be sure to check out the Security Engineering blog, which covers topics ranging from VRP updates to security practices and vulnerability descriptions!
The Hacker News
Cybersecurity news and insights
TrueConf Zero-Day Exploited in Attacks on Southeast Asian Government Networks - March 31, 2026
A high-severity security flaw in the TrueConf client video conferencing software has been exploited in the wild as a zero-day as part of a campaign targeting government entities in Southeast Asia dubbed TrueChaos. The vulnerability in question is CVE-2026-3502 (CVSS score: 7.8), a lack of integrity check when fetching application update code, allowing an attacker to distribute a tampered update,
SecurityWeek
Latest cybersecurity news
Censys Raises $70 Million for Internet Intelligence Platform - March 31, 2026
The latest funding round brings the total venture capital investment in Censys to $149 million.
The post Censys Raises $70 Million for Internet Intelligence Platform appeared first on SecurityWeek.
The Next Cybersecurity Crisis Isn’t Breaches—It’s Data You Can’t Trust - March 31, 2026
Data integrity shouldn’t be seen only through the prism of a technical concern but also as a leadership issue.
The post The Next Cybersecurity Crisis Isn’t Breaches—It’s Data You Can’t Trust appeared first on SecurityWeek.
Stolen Logins Are Fueling Everything From Ransomware to Nation-State Cyberattacks - March 31, 2026
Report shows how industrialized credential theft underpins ransomware, SaaS breaches, and geopolitical attacks, shifting security focus from prevention to detecting misuse of legitimate access.
The post Stolen Logins Are Fueling Everything From Ransomware to Nation-State Cyberattacks appeared first on SecurityWeek.
Venom Stealer Raises Stakes With Continuous Credential Harvesting - March 31, 2026
Licensed malware with built-in persistence and automation enables attackers to continuously siphon credentials, session data, and cryptocurrency assets.
The post Venom Stealer Raises Stakes With Continuous Credential Harvesting appeared first on SecurityWeek.
CrewAI Vulnerabilities Expose Devices to Hacking - March 31, 2026
Attackers can exploit the bugs through prompt injection, chaining them together to escape the sandbox and execute arbitrary code.
The post CrewAI Vulnerabilities Expose Devices to Hacking appeared first on SecurityWeek.
The Hacker News
Cybersecurity news and insights
Vertex AI Vulnerability Exposes Google Cloud Data and Private Artifacts - March 31, 2026
Cybersecurity researchers have disclosed a security “blind spot” in Google Cloud’s Vertex AI platform that could allow artificial intelligence (AI) agents to be weaponized by an attacker to gain unauthorized access to sensitive data and compromise an organization’s cloud environment. According to Palo Alto Networks Unit 42, the issue relates to how the Vertex AI permission model can be misused
SecurityWeek
Latest cybersecurity news
Google Slashes Quantum Resource Requirements for Breaking Cryptocurrency Encryption - March 31, 2026
Google researchers have shown that breaking the encryption of Bitcoin and Ethereum requires 20x fewer qubits.
The post Google Slashes Quantum Resource Requirements for Breaking Cryptocurrency Encryption appeared first on SecurityWeek.
The Hacker News
Cybersecurity news and insights
The AI Arms Race – Why Unified Exposure Management Is Becoming a Boardroom Priority - March 31, 2026
The cybersecurity landscape is accelerating at an unprecedented rate. What is emerging is not simply a rise in the number of vulnerabilities or tools, but a dramatic increase in speed. Speed of attack, speed of exploitation, and speed of change across modern environments. This is the defining challenge of the new era of digital warfare: the weaponization of Artificial Intelligence. Threat actors
Silver Fox Expands Asia Cyber Campaign with AtlasCross RAT and Fake Domains - March 31, 2026
Chinese-speaking users are the target of an active campaign that uses typosquatted domains impersonating trusted software brands to deliver a previously undocumented remote access trojan named AtlasCross RAT. “The operation covers VPN clients, encrypted messengers, video conferencing tools, cryptocurrency trackers, and e-commerce applications, with eleven confirmed delivery domains impersonating
SecurityWeek
Latest cybersecurity news
Exploitation of Critical Fortinet FortiClient EMS Flaw Begins - March 31, 2026
The SQL injection vulnerability allows unauthenticated attackers to execute arbitrary code remotely, via crafted HTTP requests.
The post Exploitation of Critical Fortinet FortiClient EMS Flaw Begins appeared first on SecurityWeek.
Trail of Bits Blog
Security research and insights from Trail of Bits
How we made Trail of Bits AI-native (so far) - March 31, 2026
This post is adapted from a talk I gave at [un]prompted, the AI security practitioner conference. Thanks to Gadi Evron for inviting me to speak. You can watch the recorded presentation below or download the slides.
Most companies hand out ChatGPT licenses and wait for the productivity numbers to move. We built a system instead.
A year ago, about 5% of Trail of Bits was on board with our AI initiative. The other 95% ranged from passively skeptical to actively resistant. Today we have 94 plugins, 201 skills, 84 specialized agents, and on the right engagements, AI-augmented auditors finding 200 bugs a week. This post is the playbook for how we got there. We open sourced most of it, so you can steal it today.
A recent Fortune article reported that a National Bureau of Economic Research study of 6,000 executives across the U.S., U.K., Germany, and Australia found AI had no measurable impact on employment or productivity. Two-thirds of executives said they use AI, but actual usage came out to 1.5 hours per week, and 90% of firms reported zero impact. Economists are calling it the new Solow paradox, referencing the pattern Robert Solow identified in 1987: “you can see the computer age everywhere but in the productivity statistics.”
AI works. Most companies are using it wrong. They give people tools without changing the system. That’s the gap between AI-assisted and AI-native. One is a tool, the other is an operating system.
What AI-native actually means
“AI-native” gets thrown around a lot. The way I think about it, there are three levels:
AI-assisted is where almost everyone starts. You give people access to ChatGPT or Claude. They use it to draft emails, generate boilerplate, summarize documents. It’s a productivity tool. The org doesn’t change. The workflows don’t change. You just do the same things a little faster.
AI-augmented is where you start redesigning workflows. You’re not just using AI as a tool. You’re putting agents in the loop, changing how work actually flows. Maybe the AI does the first pass on a code review and the human does the second. The process itself is different.
AI-native is the structural shift. The org is designed from the ground up assuming AI is a core participant. Not a tool you pick up, but a teammate that’s always there. Your knowledge management, your delivery model, your expertise, all designed to be consumed and amplified by agents.
At Trail of Bits, what this means concretely: our security expertise compounds as code. Every engagement we do, the skills and workflows we build make the next engagement faster. Every engineer operates with an arsenal of specialized agents built from 14 years of audit knowledge. That’s not “we use AI.” That’s “AI is on the team.”
What people are actually resisting
When I first launched this initiative inside Trail of Bits, there was an incredible amount of pushback. Studies of technology adoption consistently show the same thing: the problem is never the software. It’s people’s unwillingness to accept that something else might be better than their intuition. I had to understand four specific psychological barriers before I could design a system that works within them.
Self-enhancing bias. We overestimate our own judgment. Paul Meehl and Robyn Dawes showed that if you take the variables an expert says they use and build even a crude linear model, the model outperforms the expert. Not because it’s smarter, but because it applies the same weights every time. You don’t. You’re hungover some days, distracted others, and you never notice because you take credit for your wins and blame external factors for your misses. This gets worse with seniority. The more expert you are, the more you trust your gut, and the less you believe a machine could do better. As Jonathan Levav frames it: the more unique you feel you are, the more you resist a machine making decisions for you.
Identity threat. In one study, researchers showed people the same kitchen automation device framed two ways: “does the cooking for you” versus “helps you cook better.” People who identified as cooks rejected the first framing and accepted the second, for the same device. There’s a symbolic dimension too: people don’t want robots giving them tattoos (human craft), but they’re fine with a tattoo-removing robot (instrumental, no symbolism). Security auditing is symbolic work. AI that replaces skill feels like an attack on who you are.
Intolerance for imperfection. Dietvorst et al. ran a study where participants watched an algorithm outperform a human forecaster. But after seeing the algorithm make one error, they abandoned it and went back to the human, even though the human was demonstrably worse. We forgive our own mistakes but not the machine’s. Their follow-up found the fix: let people modify the algorithm. Even one adjustable parameter was enough to overcome the aversion.
Opacity. A 2021 study in Nature Human Behaviour found that people’s subjective understanding of human judgment is high and AI judgment is low, but objective understanding of both is near zero. People feel like they understand how a doctor diagnoses. They can’t explain it either. The feeling of not understanding kills the feeling of control.
The remedies that actually worked
We designed the system around the resistance, not against it.

For self-enhancing bias, we built a maturity matrix. Nobody likes being told they’re at level 1. But that’s the point: you can’t argue you’re already good enough when there’s a visible ladder. It makes the conversation concrete instead of “I don’t think AI is useful.” It also creates social proof. When you see peers at level 2 or 3, the passive majority starts moving.
For identity threat, we never asked anyone to stop being a security expert. We gave them a new way to express that identity. When a senior auditor writes a constant-time-analysis skill, they’re not being replaced. They’re becoming more permanent. Their expertise is encoded and reusable. That’s an identity upgrade, not a threat. The maturity matrix reinforces this: level 3 isn’t “uses AI the most.” It’s “invents new ways, builds tools.” The identity of the expert shifts from “I don’t need AI” to “I’m the one who makes the AI dangerous.”
For intolerance for imperfection, we invested heavily in reducing the ways AI can fail embarrassingly. A curated marketplace means no random plugins with backdoors. Sandboxing means Claude Code can’t accidentally delete your work. Guardrails and footgun reduction mean fewer “AI did something stupid” stories circulating in Slack. If someone’s first AI experience is bad, you’ve lost them for months.
For opacity, we wrote an AI Handbook that made everything concrete: here’s what’s approved, here’s what’s not, here are the exceptions, here’s who to ask. Clear rules restored the feeling of control.
And underlying everything: we made adoption visible and fast. Deferred benefits kill adoption. If setup takes an hour and the first result is mediocre, you’ve confirmed every skeptic’s priors. Copy-pasteable configs, one-command setup, standardized toolchain, all designed so the first experience is fast and good. And the CEO going first matters more than people think. The passive 50% watches what leadership actually does, not what it says.
The operating system model
Here’s the actual system we built. Six parts, each designed to address the barriers I just described:
| Barrier | Core problem | What we built |
|---|---|---|
| Self-enhancing bias | “I’m already good enough” | Maturity Matrix with visible levels and real consequences |
| Identity threat | “AI is replacing who I am” | Skills repos + hackathons that reward building, not just using |
| Intolerance for imperfection | One bad experience = months lost | Curated marketplace, sandboxing, guardrails |
| Opacity / trust | “I don’t understand how it decides” | AI Handbook that explains the risk model, not just the rules |
- Pick a standard toolchain so you can support it
- Write the rules so risk conversations stop being ad hoc
- Create a capability ladder so improvement is expected, measurable, and rewarded
- Run tight adoption sprints so the org keeps pace with releases
- Package the learnings into reusable artifacts (repos, configs, sandboxes) so the system compounds
- Make autonomy safe with sandboxing, guardrails, and hardened defaults
This isn’t a strategy deck we wrote and handed to someone. We built every piece ourselves, open sourced most of it, and iterated on it in production with a 140-person company doing real client work.
Standardize on tools
Step one was boring but critical: we standardized. We got everyone on Claude Code, and we treat it like any other enterprise tool: supported configs, known-good defaults, and a clear path to “this is how we do it here.”
If you skip this step, you can’t build anything else. You end up with 40 different workflows and zero leverage.
Write the rules
We wrote an AI Handbook. Not to teach people how to prompt. It’s there to remove ambiguity.
The key part is the usage policy: what tools are approved, what isn’t, especially for sensitive data. Cursor can’t be used on client code (except blockchain engagements; use Claude Code or Continue.dev instead). Meeting recorders are disallowed for client meetings conducted under legal privilege. Now, when a client asks what we’re using on their codebase, everyone gives the same answer.
The handbook doesn’t just list what’s approved. It explains the risk model behind each decision, so people understand why. That’s what addresses the opacity barrier: not “just trust this,” but “here’s our reasoning.” Once you have policy, you can safely push harder on adoption.
Make it measurable
We built an AI Maturity Matrix that makes AI usage a first-class professional capability, like “can you use Git” or “can you write tests.”
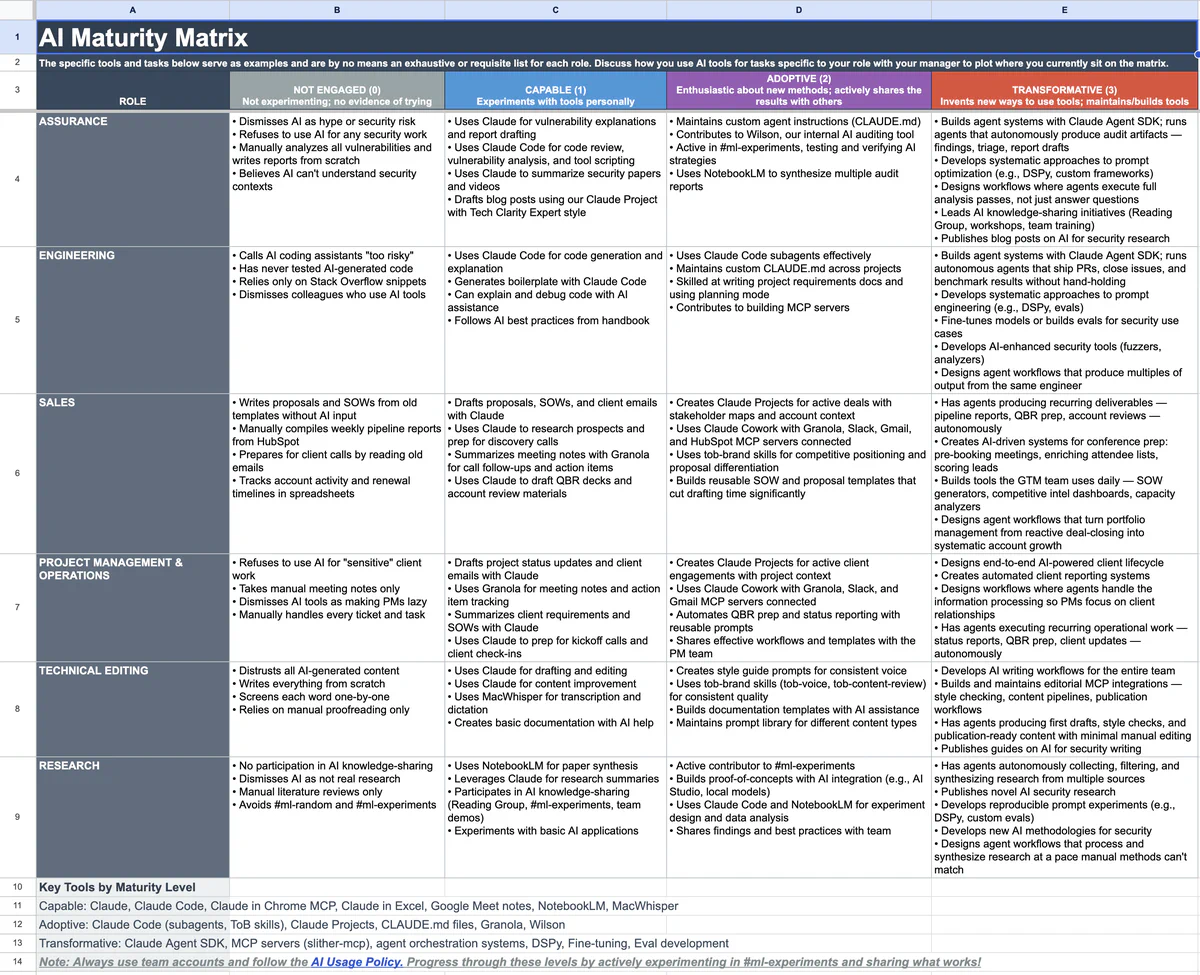
It’s not a vibe. It’s a ladder: clear levels, clear expectations, a clear path up, and real consequences for staying stuck. What level 3 looks like depends on your role. An engineer at level 3 builds agent systems that ship PRs and close issues autonomously. A sales rep at level 3 has agents producing pipeline reports and QBR prep without hand-holding. An auditor at level 3 runs agents that execute full analysis passes and produce findings, triage, and report drafts.
This is how you avoid two failure modes: leadership wishing adoption into existence, and the org splitting into “AI people” and everyone else.
Create an adoption engine
We run hackathons as a management system: short, focused sprints of 2-3 days with one objective. They’re how we keep pace when the ecosystem changes every week.
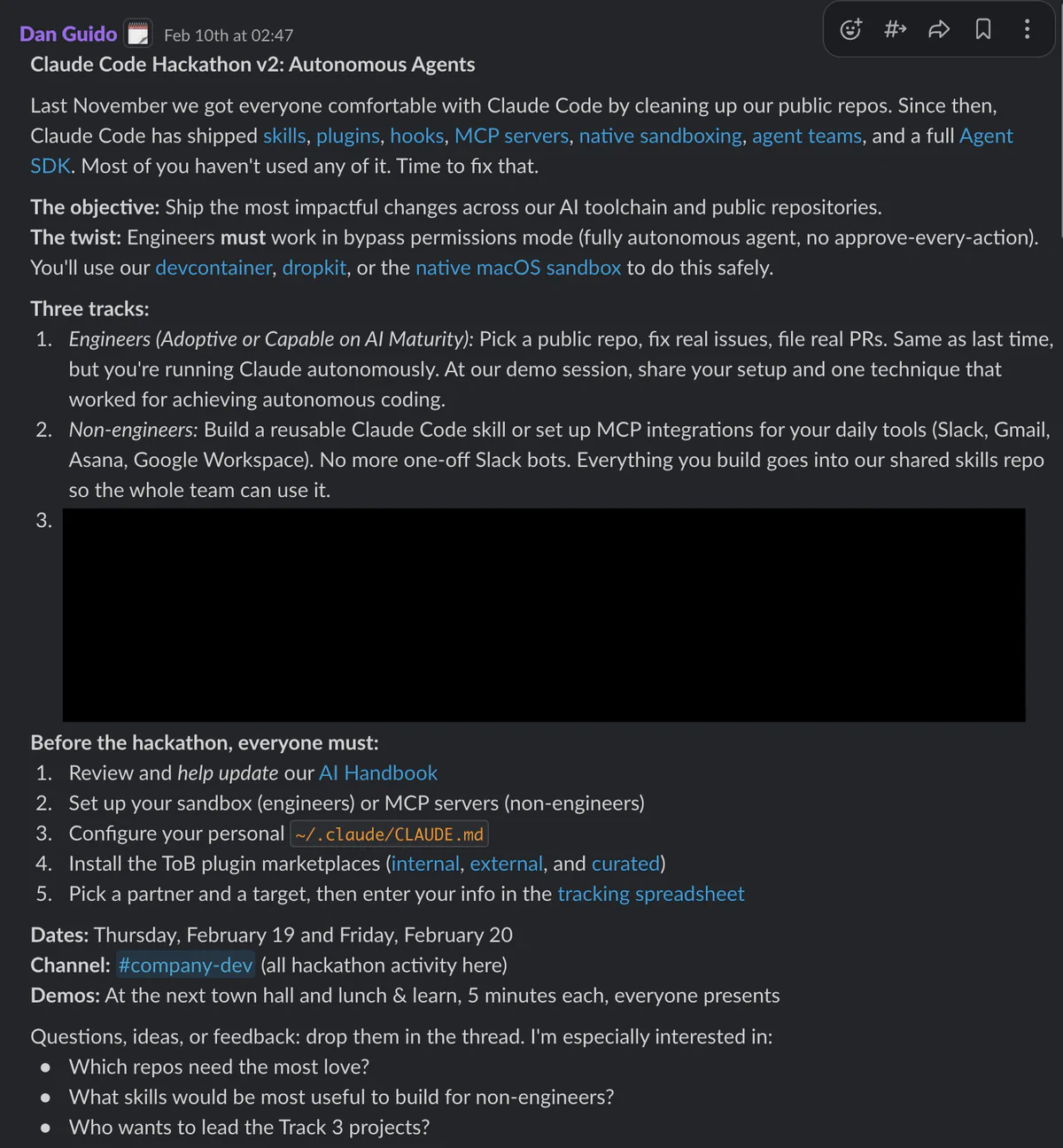
One recent example: “Claude Code Hackathon v2: Autonomous Agents.” The two lines that mattered were:
- Objective: Ship the most impactful changes across our AI toolchain and public repos
- Twist: Engineers must work in bypass permissions mode (fully autonomous agent, not approve-every-action)
That twist is intentional. It forces everyone to learn the real constraints: sandboxing, guardrails, and how to structure work so agents can succeed.
A few design choices matter here: we focus on public repos so we can move fast and show real outcomes. We measure success by activity (issues filed/fixed, PRs reviewed/merged), not lines of code. Everyone works in pairs, and every change gets reviewed by a buddy. Even the “move fast” sprint has quality control built in.
Capture the work as reusable artifacts
Hackathons create motion. But motion doesn’t compound unless you capture it.
The most important artifact is a skills repo. Skills are reusable, structured workflows, ideally with examples, constraints, and a way to verify output. We maintain an internal skills repo for company-specific workflows and an external skills repo so the broader community can validate and improve what we’re doing.
We also created a curated marketplace, a “known good” place for third-party skills. Once you tell people “go use skills and plugins,” they’ll install random stuff. This is basic enterprise thinking applied to agent tooling: if you want adoption, you need a safe supply chain.
We made defaults copy-pasteable. We built a repo that centralizes recommended Claude Code configuration so onboarding isn’t tribal knowledge. This is where we put known-good settings, recommended patterns for personal ~/.claude/CLAUDE.md, and anything we want to standardize.
We made sandboxing the default. If you want autonomous agents, you need sandboxing. We give people multiple safe lanes: a devcontainer option, native macOS sandboxing, and Dropkit. The point isn’t that everyone uses the same sandbox. The point is everyone has a safe sandbox, and it’s easy to adopt.
We reduced footguns. We hardened defaults through MDM. For example, we rolled out more secure package manager defaults via Jamf, including mandatory package cooldown policies. The easiest way to reduce risk is to make the default path the safe path.
Finally, we connected agents to real tools. Once you have policy, guardrails, sandboxes, and skills, you can connect agents to real tools. One example we’ve published is an MCP server for Slither. Even if you don’t care about Slither specifically, the point is: MCP turns your internal tools into something agents can use reliably, and your org can govern.
Results so far
Let me give you some numbers on what this system actually produced.
![The numbers that got the room’s attention at [un]prompted](https://blog.trailofbits.com/2026/03/31/how-we-made-trail-of-bits-ai-native-so-far/results_hu_d317e9018c8a275d.webp)
Tooling scale: Across our internal and public skills repos, we have 94 plugins containing 201 skills, 84 specialized agents, 29 commands, 125 scripts, and over 414 reference files encoding domain expertise. That’s the compounding effect: every engagement, every auditor, every experiment adds to the arsenal.
The breadth matters. We have skills for writing sales proposals, tracking project hours, onboarding new hires, prepping conference blog posts, and delivering government contract reports. The internal repo has 20+ plugins targeting specific vulnerability classes: ERC-4337, merkle trees, precision loss, slippage, state machines, CUDA/Rust review, integer arithmetic in Go. Each one packages expertise that used to live in someone’s head into something any auditor can invoke.
Delivery impact: For certain clients where the codebase and scope allow it, we went from finding about 15 bugs a week to 200. An auditor runs a fleet of specialized agents doing targeted analysis across an entire codebase in parallel, then validates the results.
About 20% of all bugs we report to clients are now initially discovered by AI in some form. They go into real client reports. An auditor validates every one, but the AI is surfacing things humans would have missed or wouldn’t have had time to look for.
Business impact: Our sales team averages $8M in revenue per rep against a consulting industry benchmark of $2-4M. The sales team uses the same skills repos for proposal drafting, competitive positioning, conference prep, and lead enrichment. Same system, same compounding effect.
And this is maybe a year into building the system seriously. The models are getting better every month. The skills repo grows every week.
Open questions
Here’s what we’re actively working on and don’t have great answers for yet.
Private inference. We want local models for cost and confidentiality, but open models aren’t good enough yet. There’s still a significant gap versus the best closed models on coding benchmarks. We’re evaluating on-prem inference servers to run 230B+ models at full precision. Key insight: speed drives adoption more than capability. Nobody uses a slow model, even if it’s smart. In the meantime, private inference providers like Tinfoil.sh (confidential computing on NVIDIA GPUs, cryptographically verifiable) are getting compelling.
Prompt injection and client code protection. This is an existential question for using AI on client code. The data the agent works on is inherently accessible to it. Today we use blunt instruments: sensitive clients mean no web access. Longer term, we’re looking at agent-native shells like nono and agentsh that enforce policy at the kernel level.
Policy enforcement and continuous learning. We push settings via MDM, but we’re not yet pulling signal back. The goal is to turn the whole company into a feedback loop that improves the operating system weekly. One possible long-term architecture: a master MCP server between agents and internal resources, enforcing policy server-side. We’re not there yet.
The future of consulting. This is the one that keeps me up at night. The consulting business model assumes you’re billing for time, and that time roughly correlates with expertise. But when some people can outperform others by orders of magnitude with the right agent setup, that correlation breaks. The question shifts from “how many hours did the auditor spend” to “did the auditor know where to point the agents and which findings are real.”
We don’t have the answer yet. But the nature of how Trail of Bits offers services will probably change in the next 6 to 12 months. Audit scoping, pricing, deliverables, all of it is on the table. The firms that figure this out first will have a structural advantage, and the ones that keep billing by the hour will watch their margins compress as their competitors ship more in less time. We’re not waiting to find out which side we’re on.
The replicable recipe
If you want to copy this, copy the system, not the specific tools:
- Standardize on one agent workflow you can support
- Write an AI Handbook so risk decisions aren’t ad hoc
- Create a capability ladder so improvement is expected
- Run short adoption sprints that force hands-on usage
- Capture everything as reusable artifacts: skills + configs + curated supply chain
- Make autonomy safe with sandboxing + guardrails + hardened defaults
That’s what we’ve done so far, and it’s already changed how fast we can ship and how quickly we can adapt.
Resources
All of our tooling is open source:
- trailofbits/skills - Our public skills repository
- trailofbits/skills-curated - Curated third-party skills marketplace
- trailofbits/claude-code-config - Recommended Claude Code configurations
- trailofbits/claude-code-devcontainer - Devcontainer for sandboxed development
- trailofbits/dropkit - macOS sandboxing for agents
- trailofbits/slither-mcp - MCP server for Slither
We’re hiring! We’re looking for an AI Systems Engineer to work directly with me on accelerating everything in this post, and a Head of Application Security to lead a team of about 15 exceptionally overperforming consultants. Check out trailofbits.com/careers.
SecurityWeek
Latest cybersecurity news
StrongSwan Flaw Allows Unauthenticated Attackers to Crash VPNs - March 31, 2026
Remotely exploitable, the integer underflow vulnerability impacts StrongSwan releases spanning 15 years.
The post StrongSwan Flaw Allows Unauthenticated Attackers to Crash VPNs appeared first on SecurityWeek.
The Hacker News
Cybersecurity news and insights
Axios Supply Chain Attack Pushes Cross-Platform RAT via Compromised npm Account - March 31, 2026
The popular HTTP client known as Axios has suffered a supply chain attack after two newly published versions of the npm package introduced a malicious dependency that delivers a trojan capable of targeting Windows, macOS, and Linux systems. Versions 1.14.1 and 0.30.4 of Axios have been found to inject “plain-crypto-js” version 4.2.1 as a fake dependency. According to StepSecurity, the two

